반응형
Q1.
vector<int32> v;
void Push()
{
for (int32 i = 0; i < 10000; i++)
{
v.push_back(i);
}
}
int main()
{
std::thread t1(Push);
std::thread t2(Push);
t1.join();
t2.join();
cout << v.size() << endl;
}여기서 왜 크래쉬가 났을까?
Q2. v.reserve(20000);를 추가했을 때 크래쉬는 안나지만 왜 size가 20000이 안될까?
Q3. atomic<vector<int32>> a;을 사용할 수 없으니 뭘 사용해야 할까?
Q4. lock, unlock을 재귀적으로 호출할 수 있는가?
Q5. lock을 안풀면 어떻게 되나?
Q6. 규모가 큰 경우에는 lock을 어떻게 관리 하나?
Q7. lock_guard와 unique_lock의 차이점은?
Q8. lock의 위치에 따라 뭐가 달라지는가?
atomic 보다 일반적인 상황에서 활용하는게 lock
vector<int32> v;
void Push()
{
for (int32 i = 0; i < 10000; i++)
{
v.push_back(i);
}
}
int main()
{
std::thread t1(Push);
std::thread t2(Push);
t1.join();
t2.join();
cout << v.size() << endl;
}
이런 코드가 있다고 가정을 해보자.
이 상태에서 f5를 눌러 실행을 하면 데이터가 2만개가 되기는 커녕 크러쉬가 나는 걸 알 수가 있다.
이제까지 배운 STL에서 사용하던 자료구조 컨테이너들은 멀티스레드 환경에서는 동작하지 않는다는 가정을 해야 한다.
vector는 기본적으로 동적 배열
// [1][2][3] 이 배열이 꽉 차면 더 큰 영역을 할당 받아서
// [1][2][3][ ][ ][ ] 복사를 하고 원래 있던 메모리는 날려 준다.
여기까지만 봐도 아차 싶어.
멀티 스레드는 다른 스레드를 기다려주지 않아.
1,2,3까지 받아준 상태에서 push가 양쪽에서 진행이 된다면
첫번째가 간발의 차이로 push_back을 실행을 할 때 용량이 꽉 찼으니까 더 큰 메모리를 할당 받고, 복사를 하고 원래 것을 삭제하려고 시도를 할 거야.
그런데 그와 동시에 t2라는 다른 스레드에서도 같은 행동을 하려고 꽉 찼으니까 더 큰 영역을 받고 지워야지 하는데
이미 t1이 이미 삭제한 상태가 될 수도 있어. 그렇게 되면 이미 삭제된 걸 또 삭제하려니까 double free가 발생해서 그래서 crash가 난다고 예측을 할 수 있다.
이게 vector가 아니라 list나 다른 자료구조라고 하면 다른 이유로 crash가 나겠지만 어쨌든 기본적으로 각기 동작하는 방식이 싱글스레드에서 동작하던 것이라 문제가 있다.
그러면 이 문제를 해결하기 위해서
v.reserve(20000);
이렇게 해주면 crash 없어지지 않을까?
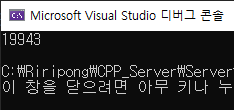
실행을 해보면 crash는 나지 않지만 20000개가 아니라 몇 개가 분실 되었다는 걸 알 수 있다.
만약 거의 동시 다발적으로 t1, t2가 호출이 된다면 하나가 완전히 쓰는 게 완료되지 않은 상태에서 같은 위치에 데이터를 2번 기입하는 상황이 발생할 수 있다.
그렇기 때문에 결국에는 데이터가 20000개가 완전히 채워지지 않는 상황이 발생할 수 있다.
그래서 사실 크래시가 나지 않았지만 크레시가 나서 원인을 찾는게 낫다. 통과 됐는데 일부 데이터 분실하면 더 버그 찾기 어려워.
결국 공유해서 사용하는 데이터를 동시에 접근해서 사용하는 건 말이 안된다.
그렇다고 atomic을 사용하면
atomic<vector<int32>> a;
이런 경우는 쓸 수가 없어. store나 load 같은 거를 사용할 수 있지만 vector의 세부적인 기능을 사용할 수 있다는 말이 아니기 때문에 atomic을 여기서는 사용할 수 없다.
여기서 해야 할 건 puch_back을 하는 동안에, 즉 vector<int32> v를 건드리는 동안에 다른 애들은 이 벡터를 건드리지 못하도록 서로 신호를 정해주는 것처럼 순서를 정해서 한번에 1명만 접근하도록 유도를 해줘야 하는데 그게 기본적으로 lock의 개념이라고 할 수 있다.
lock 도 운영체제마다 방법이 있어서 windows에서는 CriticalSection을 사용하고 분할이 되어 있었는데 마찬가지로 C++11에서 통합이 되면서
#include <mutext>
라는 헤더를 추가해서
공유해서 사용할 뮤텍스를
mutex m;
이렇게 만들어 주고
얘가 일종의 자물쇠라고 생각하면 된다. 기내의 화장실을 생각하면 되는데 화장실을 보면 1인실로 되어 있어.
안에 들어가서 자물쇠를 잠그면 밖에 있는 사람에게는 빨간색으로 뜨게 된다.
안에 있는 사람이 자물쇠 풀고 나오면 들어갈 수 있어.
먼저 들아갈 애가 lock이라는 걸
m.lock();
이렇게 실행해 줄거야.
lock을 하면 내가 화장실을 차지한 거니까 다른 애들은 접근을 할 수 없는 상태가 된거다.
볼일을 다 보고 데이터를 다 건드렸으면 이제 풀어줘야해.
m.unlock();
이렇게 lock 과 unlock 이 세트로 동작을 한다.
vector<int32> v;
mutex m;
void Push()
{
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
m.lock();
v.push_back(i);
// 자물쇠 풀기
m.unlock();
}
}
int main()
{
v.reserve(20000);
std::thread t1(Push);
std::thread t2(Push);
t1.join();
t2.join();
cout << v.size() << endl;
}
내가 이미 자물쇠를 획득한 상태에서 다른 애가 똑같은 코드를 실행하면 그냥 m.lock에서 대기를 타게 된다.
다른 애가 unlock으로 풀어주기 전까지는 접근을 하지 못한다.
순차적으로 접근을 보장해주는 잠금장치라고 보면 된다.
물론 얘를 막 사용하는게 좋은 건 아닌게 여기서 한번에 한명만 통과를 할 수 있기 때문에
// 자물쇠 잠그기
m.lock();
v.push_back(i);
// 자물쇠 풀기
m.unlock();
요 코드 자체는 싱글스레드로 동작하는 개념이라고 볼 수 있다.
v.reserve(20000); 를 없애고 실행해보면
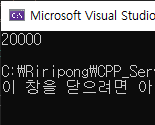
20000개가 들어 가는 거 알 수 있지만
그럼에도 lock과 unlock을 하는 경합이 있기 때문에 일반적인 상황보다는 느리게 동작할 수 밖에 없게 된다.
이게 기본적인 lock의 개념이라고 볼 수 있다.
// Mutual Exclusive (상호 배타적)
내가 먼저 락을 획득했으면 다른 누군가는 절대로 동작을 할 수 없다.
나만 사용할거야. 이기적으로 락을 잠그는 것이기 때문에 상호 베타적이라는 특성을 갖고 있다.
여기서 몇 가지 조심해야 하는 부분이 있다.
다양한 락에 대해서 실습을 할 것인데 일단
1. 락을 재귀적으로 걸 수 있느냐도 중요한 문제다.
mutex 같은 경우에는 재귀적으로 호출을 할 수가 없다.
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
m.lock();
m.lock();
v.push_back(i);
// 자물쇠 풀기
m.unlock();
m.unlock();
}
이런 상황이 되면 바로 크래쉬가 난다.
재귀적인 것을 허용하는 mutex가 따로 존재한다.
이런 부분도 주의 깊게 볼 부분.
재귀적으로 잠글 필요가 있을까?
나중에 코드가 복잡해지면, 간단하게 push_back하고 끝내는 게 아니라
내부에서도 다른 함수를 호출하고 다른 함수가 또 함수를 호출하는 경우가 있는데 함수 내부에서도 lock을 잡을 수 있기 때문에 재귀적으로 lock을 허용하는 경우가 컨텐츠 개발을 할 때 조금 더 편하다. 그래야지 만들어 놓은 함수를 재사용해서 호출 할 수 있어.
두번째로 신경쓸 문제는
2. lock을 잡았는데 어떤 실수를 해서 lock을 안플어 주면 어떻게 되는 거냐면
화장실 문을 잠그고 문으로 나오지 않고 창문으로 나가는 그런 상황.
그 화장실은 다른 사람이 접근할 수 없는 끔찍한 상황이 되는 거.
그런 초보적인 실수를 누가 햐냐 싶긴 한데,
그럼에도 실수를 하는 이유는
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
m.lock();
// m.lock();
v.push_back(i);
if (i == 5000)
break;
// 자물쇠 풀기
m.unlock();
// m.unlock();
}
어떤 예외적인 상황에서 break가 나오면, 원래는 lock, unlock 세트를 지켜줘야 되는데
만약에 i가 5000에 들어와서 break 하면 unlock안하고 빠져나가는 상황.

프로그램이 끝나지 않고 돌아간다고 볼 수 있어. 모두 중단을 눌러서 보면 lock에서 무한 대기를 하는 상황이 발생한다.
그러면 break를 하기 전에 내가 lock을 잡았으면 반드시 요 lock 도 풀어줘야 하는게 누락 되어 발생한 거.
if (i == 5000)
{
m.unlock();
break;
}
하지만 한 땀 한 땀 lock 해주고 풀어주는게 피곤한 일이 될거야.
간단한 경우가 아니라 복잡한 함수는 몇 천 줄 까지 갈 수 있어.
수동으로 lock 잠그고 푸는 건 작은 함수라면 괜찮지만 조금 규모가 큰 경우면 수동으로 관리 하는 건 나쁜 습관이라 볼 수 있다.
C++의 유명한 패턴 중에서
// RAII (Resource Acquisition Is Initialization) (리소스 획득이 초기화됨)
이런게 있는데
어떤 wrapper 클래스를 만들어가지고 생성자에서 잠그고 소멸자에서 풀어주고 하는 행동을 하게 된다.
lock에 대해서만 하는게 아니라 다른 resource 나 DB 연결할 때도 동일한 패턴으로 사용하게 될 거야.
template<typename T>
class LockGuard
{
public:
LockGuard(T& m)
{
_mutex = &m;
_mutex->lock();
}
~LockGuard()
{
_mutex->unlock();
}
private:
T* _mutex;
};
말 그대로 이 객체는 해당하는 _mutex를 자동으로 잠궈주고, 자동으로 열어주는 역할을 하기 위해 존재하는 wrapper class라고 볼 수 있다.
이제 lock 과 unlock을 직접 명시적으로 호출하는게 아니라 LockGuard라는 아이를 만들어 주는 거다.
void Push()
{
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
LockGuard<std::mutex> lockGuard(m);
// m.lock();
// m.lock();
v.push_back(i);
if (i == 5000)
{
// m.unlock();
break;
}
// 자물쇠 풀기
// m.unlock();
// m.unlock();
}
}
lockGuard(m)가 선언될 때 생성자가 실행 되면서 lock을 걸어주고
범위를 벗어나면 소멸 되면서 unlock을 실행하게 될 거다.
이렇게 해서 자동으로 잠궈주는 자동문을 만들어 줬다고 볼 수 있다.
이런 상황이라면 아까 처럼 무한으로 대기하는 상황 없이 자동으로 락이 풀어질 것이기 때문에 실질적으로 코드를 실행해 보면 정상적으로 종료가 될 거라는 거 확인할 수 있을 것이다.
이런식으로 LockGuard를 이용해 mutex를 사용하는 게 좋다고 할 수 있다.
물론 이 객체를 만드는 부하가 추가 되겠지만 안전한 코드를 짜는게 더 중요한다.
매번마다 직접 만들어야 하는 건 아니고 표준에도 들어가 있다.
std::lock_guard<std::mutex> lockGuard(m);
이렇게 하면 똑같이 동작하게 된다.
뮤텍스 자동으로 걸고 풀게 되면 짝을 안맞춰서 생기는 상황을 예방할 수 있다.
lock_guard 말고 또 다른 버전은
std::unique_lock<std::mutex> uniqueLock(m);
완전히 똑같진 않아. 이렇게 만들어 놨으면 lock_guard에다가 추가적으로 기능이 있어.
당장 lock을 잠그지 않고, 옵션을 줘서
std::unique_lock<std::mutex> uniqueLock(m, std::defer_lock);
defer_lock이란 옵션을 주면 당장 잠그진 않을 것이고, 일단은 인터페이스만 준비를 해주고
실질적으로
uniqueLock.lock();
이렇게 잠그는 순간에 똑같이 동작을 하게 된다.
만들자 마자 잠그는게 아니라 잠그는 시점을 뒤로 넘길 수 있다.
lock_guard 보다 약간 느리므로 간단할 때는 lock_guard를 쓰고,
잠그는 시점 미뤄야 할 때는 unique_lock을 사용한다.
단순하지만 생각할게 많아.
for문 내부에서 잡아도 되지만, 밖에서 크게 잡아도 된다.
락 거는 범위에 따라 많은 것이 달라진다.
void Push()
{
std::lock_guard<std::mutex> lockGuard(m);
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
// LockGuard<std::mutex> lockGuard(m);
// std::lock_guard<std::mutex> lockGuard(m);
// LockGuard<std::mutex> uniqueLock(m, std::defer_lock);
// uniqueLock.lock();
// m.lock();
// m.lock();
v.push_back(i);
if (i == 5000)
{
// m.unlock();
break;
}
// 자물쇠 풀기
// m.unlock();
// m.unlock();
}
}
이렇게 크게 잡아주면
for문 안에 있는 모든 일감이 완료 되기 까지는 다른 애들은 입구에서 컷이 되어서 for문 밖에서 대기를 해야 하는 거고,
그게 아니라
void Push()
{
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
// LockGuard<std::mutex> lockGuard(m);
std::lock_guard<std::mutex> lockGuard(m);
// LockGuard<std::mutex> uniqueLock(m, std::defer_lock);
// uniqueLock.lock();
// m.lock();
// m.lock();
v.push_back(i);
if (i == 5000)
{
// m.unlock();
break;
}
// 자물쇠 풀기
// m.unlock();
// m.unlock();
}
}
for 문 내부에서 잠궜다고 하면
for문에 들어 올 때 마다 lock을 걸었다 풀었다 하게 된다.
이런 식으로 범위가 왔다 갔다 하는 걸 유의 깊게 보면 된다.
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic>
#include <mutex>
// [1][2][3]
// [1][2][3][ ][ ][ ]
vector<int32> v;
// atomic<vector<int32>> a;
// Mutual Exclusive (상호배타적)
mutex m;
// RAII (Resource Acquisition Is Initialization)
template<typename T>
class LockGuard
{
public:
LockGuard
(T& m)
{
_mutex = &m;
_mutex->lock();
}
~LockGuard()
{
_mutex->unlock();
}
private:
T* _mutex;
};
void Push()
{
// std::lock_guard<std::mutex> lockGuard(m);
for (int32 i = 0; i < 10000; i++)
{
// 자물쇠 잠그기
std::lock_guard<std::mutex> lockGuard(m);
// std::unique_lock<std::mutex > uniqueLock(m, std::defer_lock);
// uniqueLock.lock();
// m.lock();
// m.lock();
v.push_back(i);
if (i == 5000)
{
// m.unlock();
break;
}
// 자물쇠 풀기
// m.unlock();
// m.unlock();
}
}
int main()
{
// v.reserve(20000);
std::thread t1(Push);
std::thread t2(Push);
t1.join();
t2.join();
cout << v.size() << endl;
}
반응형
'Server programming' 카테고리의 다른 글
| 02_08_멀티쓰레드 프로그래밍_Sleep (0) | 2022.08.05 |
|---|---|
| 02_07_멀티쓰레드 프로그래밍_SpinLock (0) | 2022.08.05 |
| 02_06_멀티쓰레드 프로그래밍_Lock 구현 이론 (0) | 2022.08.03 |
| 02_05_멀티쓰레드 프로그래밍_DeadLock (0) | 2022.08.03 |
| 02_03_멀티쓰레드 프로그래밍_Atomic (0) | 2022.07.29 |

댓글