Server programming
02_03_멀티쓰레드 프로그래밍_Atomic
devRiripong
2022. 7. 29. 16:48
반응형
Q.힙, 스택, 데이터 영역의 차이는? 예를 들어 설명하시오.
Q. 왜 멀티 쓰레드로 전역 변수를 수정하면 결과가 이상하게 나오는지 설명하시오.
Q. atomic을 사용하면 왜 제대로 값이 나오는지 원리를 설명해 보시오.
Q. atomic의 단점은?
이번시간은 멀티스레드 환경에서 공유 데이터 사용할 때 일어나는 문제점 알아볼거야.

이렇게 하면 당연히 값은 0이 출력된다.

하지만 이번에는 각각의 스레드로 실행을 하게 되면

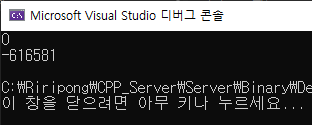
0이 아닌 할 때 마다 엉뚱한 다른 값이 나온다.
왜 당연히 0이 안되는 걸까?
stack 같은 경우는 각기 자신의 영역을 따로 가지고 있다. 만약 sum 변수가 Add() 함수 내부에 있다면
void Add()
{
int sum = 0 ;
for (int i = 9; i < 100'0000; i++)
{
sum++;
}
}
sum은 stack 메모리에 올라가는 데이터이기 때문에 다른 애들의 영향을 전혀 받지 않는다.
그런데 heap이나 데이터 영역 같은 경우에는 스레드끼리 서로 공유하며 하는 것이기 때문에 전역에 올라와 있는 데이터라 한다면 두 스레드에서 서로 경합해서 건드리고 있는 상황이다.
어떤 변수를 보면 heap, stack, 데이터 영역인지 구분할 수 있어야 해.
sum++에 중단점 찍고 실행 한 후
디버그-->창->디스어셈블리
어셈블리 명령어로 볼 수 있는 창이 있어.
{
sum++;
00007FF78F252765 mov eax,dword ptr [sum (07FF78F25F440h)] 어떤 주소에 있는 데이터 영역에서 값을 가져와서 eax 레지스터에 이동 시킨 다음에
00007FF78F25276B inc eax eax레지스터의 값을 1 증가시키고
00007FF78F25276D mov dword ptr [sum (07FF78F25F440h)],eax 결과물을 원래 있던 메모리에 다시 갖다 놓는다는 걸 볼 수 있다.
}
sum++이 이 세 단계로 이루어져 있는 것을 알 수 있다.
겉으로는 sum++ 한 줄로 보였겠지만 실질적으로 compile이 되어 가지고 cpu가 실행을 할 때는 한 줄이 아니라는 것.
이걸 의사 코드로 표현을 하면
int32 eax = sum;
eax = eax + 1;
sum = eax;
이게 사실상 실제로 일어난 일이다.
마찬가지로 Sub()는 1을 줄인다고 볼 수 있다.
int32 eax = sum;
eax = eax - 1;
sum = eax;
왜 한방에 실행하지 않고 굳이 3단계로 하는 것인가?
이건 어쩔 수 없어. CPU가 어떤 메모리에 있는 값을 꺼내오고 거기다가 연산을 하는 두 가지 행동을 동시에 할 수 없게 CPU 설계가 되어 있기 때문
결국 한 줄로 표현했던 게 3 줄로 나뉘어 있다는 걸 알 수 있는 거.
물론 int32 eax 이걸 스텍에 가져오는 게 아니라 CPU 에 있는 레지스터 라고 있는 메모리에 들어가 있는 거.
그래서 이름도 eax(Extended Accumulator Register)
이 상황에서 무엇이 문제가 되는지 생각을 해보면 100만번이 아니라 1번씩 실행된다 가정을 해보자 .
하지만 multi thread 환경이다 보니까 add라는 애랑 sub 라는 애랑 동시에 두개가 같이 실행되는 상황이라고 가정하자.
int32 sum = 0;
void Add()
{
for (int32 i = 0; i < 100'0000; i++)
{
int32 eax = sum;
eax = eax + 1;
sum = eax;
}
}
void Sub()
{
for (int32 i = 0; i < 100'0000; i++)
{
int32 eax = sum;
eax = eax - 1;
sum = eax;
}
}
int main()
{
Add();
Sub();
cout << sum << endl;
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}
에서
일단 Add()와 Sub()가 동시에 실행되면
int32 eax = sum;
이 부분이 실행이 될텐데
일단 eax =0이 들어가 있을 거야.
Sub() 도 sum에 접근해 실행할테니 eax = 0
다음 줄 실행하면 Add()에서 eax = 1 되고
sum =1 이 된다.
Sub() 실행하는 스레드에서는 eax = -1되고,
sum=-1 된다.
동시에 실행될 것이기 때문에 Add, Sub 뭐가 먼저 실행될지 모르겠지만 Add 부터 실행이 됐으면 그 다음에 Sub에서 sum = -1로 값을 덮어 써서
최종적으로 sum은 -1이 될 것이고
그게 아니라 Sub가 간발의 차이로 먼저 실행이 됐다면
Add 실행하는 애가 최종 값을 1로 덮어쓰게 된다.
이걸 100만번 하게 되면 데이터가 틀어질 확률이 더 늘어나게 되는 거.
정확하게 0으로 떨어지는게 아니라 엉뚱한 값이 들어가는 이유가
이런 로직이 3단계에 걸쳐 일어나고, 서로 상대방이 데이터를 건드린다는 걸 인지하지 않고 연산을 하고 있기 때문에 발생하는 문제라고 볼 수 있다.
이게 멀티 스레드의 문제.
데이터 공용 활용이 장점이긴 해. 메모리를 힙이나 데이터 영역에 두고 서로 쓸 수 있으면 아름답게 동작하는 상황이지만 수정하기 시작하면 문제가 된다.
데이터 상태 꼬이는 문제가 일어날 수 있어.
결국 sum++이 한번에 일어나야 해.
순서가 보장이 되어야 한다.
1늘리거나 1을 늘리지 않거나 하나의 상황만 존재해야 하는데 3단계에 걸쳐 일어나다 보니 발생한 문제.
한번에 3단계가 일어나면 문제 발생 안해.
방법 중에 atomic 하게 만드는게 있어.
atom이란 건 물리에서 원자를 말한다.
원자라는 더 작게 쪼개지지 않는 최소 단위.
atomic이 표현하고 싶은 의미는 다 실행하거나 다 실행이 안되거나 둘 중 하나의 상황만 존재할 수 있는 것을 아토믹 연산이라고 한다.
// atomic : All-Or-Nothing
멀티스레드 뿐만 아니라 나중에 데이터 베이스에서도 이런 문제가 발생할 수 있따.
DB
A라는 유저 인벤에서 집행검 빼고
B라는 유저 인벤에 집행검을 추가
이게 한번에 일어나야지만 정상적인 상황이라고 할 수 있어.
하지만 크래쉬 일어나면 A만 아이템 빼앗기고 B는 얻지 못하는 상황 발생할 수 있다.
DB에서도 아토믹한 연산 유도해줘야 하는 상황 있는데 지금과 비슷한 상황.
이루어지려면 한번에, 안이루어지려면 다 안이루어져야 한다.
윈도우즈에 InterlockedAdd()라는 게 있어. 얘도 통합이 되어서 C++표준에서
atomic이라는 헤더를 추가를 하면 리눅스건 윈도우즈건 다 똑같이 동작을 하게 만들 수 있어.
atomic<int32> sum = 0;
이렇게 atomic으로 int32를 묶어 주기만 하면 된다 . atomic이 template 클래스로 되어 있기 때문.
이상태로 sum++을 하면
세단계로 되어 있던 거로 이루어 지는게 아니라, 다 이루어지거나 한번에 실행하게 된다.
sum++이라고 하면 이게 atomic인지 헷갈리니까
sum.fetch_add(1) 이런식으로 하기도 한다. 결과적으론 똑같다.
이 상황에서 실행을 해보면

0으로 나오는 것을 알 수 있다.
공유 데이터를 다루고 있을 때는 이런 문제들이 계속 발생한다.
왜 문제가 해결이 되냐면, 경합을 해서 Add 스레드가 간발의 차로 실행이 되면 sum.fetch_add(-1)은 실행되지 않고 sum.fetch_add(1)이 끝날 때 까지 대기를 하게 된다.
순서대로 누가 대기하게끔 만들어 주는 건 CPU다. sum.fetch_add(1) 하는 동안에는 sum.fetch_add(-1)이 해당 메모리에 접근해서 데이터를 갖고 오고 하는걸 막아버린다.
sum.fetch_add(1)에 중단점 걸어서 살펴보면
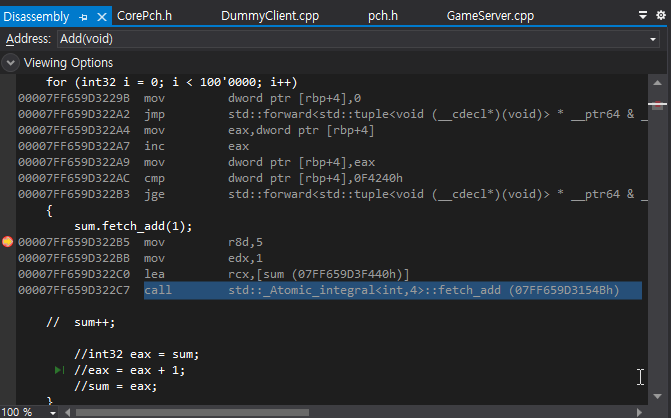
sum.fetch_add(1);
00007FF6298222B5 mov r8d,5
00007FF6298222BB mov edx,1
00007FF6298222C0 lea rcx,[sum (07FF62982F440h)]
00007FF6298222C7 call std::_Atomic_integral<int,4>::fetch_add (07FF629821550h)
달라져 있다는 걸 볼 수 있어. 세 단계가 아니라 어떤 함수를 이용해서 실행하고 있는데 내부적으로 보면 다른 cpu 인스트럭션을 이용해서 구현이 되어 있을거야.
멀티스레드에서는 무조건 atomic으로 범벅하면 되지 않을까 싶지만 atomic 하면 연산 생각보다 느리다. 정말 필요할 때만 사용해야한다.
하나가 실행이 될 때 다른 건 실행 못하니까 병목현상이 일어날 수도 있다는 걸 염두해 둬야 한다.
이게 첫번째 동기화 방법이고 이거 말고도 다른 동기화 방법이 있어.
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic>
atomic<int32> sum = 0;
void Add()
{
for (int32 i = 0; i < 100'0000; i++)
{
sum.fetch_add(1);
// sum++;
//int32 eax = sum;
//eax = eax + 1;
//sum = eax;
}
}
void Sub()
{
for (int32 i = 0; i < 100'0000; i++)
{
sum.fetch_add(-1);
// sum--;
//int32 eax = sum;
//eax = eax - 1;
//sum = eax;
}
}
int main()
{
Add();
Sub();
cout << sum << endl;
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}
반응형